Note
Click here to download the full example code
Optimizable Pipelines#
Note
These examples are basically copies from the same examples in tpcp, but using gait algorithms! These examples are less often updated than the official tpcp examples. Hence, it makes sense to cross-check the official examples.
Some gait analysis algorithms can actively be “trained” to improve their performance or adapt it to a certain dataset.
In gaitmap we use the term “optimize” instead of “train”, as not all algorithms are based on “machine learning” in the
traditional sense.
We consider all algorithms/pipelines “optimizable” if they have parameters and models that can be adapted and optimized
using an algorithm specific optimization method.
For example the BarthDtw is “optimizable”, as the template can be explicitly
learned from data.
Algorithms that can only be optimized by brute force (e.g. via GridSearch) are explicitly excluded from this group.
For more information about the conceptional idea behind this, see the guide on
algorithm evaluation.
As optimization might depend on the dataset and pre-processing, the actual optimization method is expected to be implemented on a pipeline level. Helper functions and methods for specific algorithms are of course available to minimize the implementation effort.
This example shows how such a pipeline should be implemented and how it can be optimized using
Optimize.
import numpy as np
import pandas as pd
The Dataset#
We will use a simple dataset that considers the left and the right foot of our example data as seperate datapoints. For more information on this dataset see the gridsearch guide.
from tpcp import Dataset
from gaitmap.example_data import get_healthy_example_imu_data, get_healthy_example_stride_borders
from gaitmap.stride_segmentation import TrainableTemplateMixin
from gaitmap.utils.array_handling import iterate_region_data
class MyDataset(Dataset):
@property
def sampling_rate_hz(self) -> float:
return 204.8
@property
def data(self):
self.assert_is_single(None, "data")
return get_healthy_example_imu_data()[self.index.iloc[0]["foot"] + "_sensor"]
@property
def segmented_stride_list_(self):
self.assert_is_single(None, "data")
return get_healthy_example_stride_borders()[self.index.iloc[0]["foot"] + "_sensor"].set_index("s_id")
def create_index(self) -> pd.DataFrame:
return pd.DataFrame({"participant": ["test", "test"], "foot": ["left", "right"]})
The Pipeline#
Our pipeline will implement all the logic on how our algorithms are applied to the data and how algorithms should
be optimized based on train data.
This requires two methods to be implemented: run and self_optimize.
Further, the pipeline must be a subclass of OptimizablePipeline.
In this example, we implement a simple stride segmentation using BarthDtw in
the run method.
This means we need rotate the data into the correct coordinate system depending on the foot and then apply the Dtw
method.
As our primary outcome, we store the segmented stride list (segmented_stride_list_).
To further compare the output of the method before and after optimization, we also store the cost function (
cost_func_).
For optimization (self_optimize), we extract all strides from the provided dataset and average them all into a
new template.
To decide how to average these strides, we pick a template base-class that has the interpolation method we want.
Then we can call self_optimize of this template class to generate a template from our data.
We apply additional scaling to make the final warping cost comparable to the
BarthOriginalTemplate that is used as default template.
Note
The self_optimize method must only modify parameters of the pipeline (inputs settable via the __init__).
It further must return self.
Optimize uses some checks to try to detect wrong self_optimize methods, but it will not be able to
catch all potential issues.
from tpcp import CloneFactory, OptimizableParameter, OptimizablePipeline, PureParameter
from gaitmap.stride_segmentation import BarthDtw, BarthOriginalTemplate, BaseDtwTemplate, InterpolatedDtwTemplate
from gaitmap.utils.coordinate_conversion import convert_left_foot_to_fbf, convert_right_foot_to_fbf
from gaitmap.utils.datatype_helper import SingleSensorStrideList
class MyPipeline(OptimizablePipeline):
max_cost: PureParameter[float] # This is a pure parameter, as the output of `self_optimize` does not depend on it
template: OptimizableParameter[BaseDtwTemplate] # This is the parameter that is optimized in `self_optimize`
segmented_stride_list_: SingleSensorStrideList
cost_func_: np.ndarray
# We need to wrap the template in a `CloneFactory` call here to prevent issues with mutable defaults!
def __init__(
self, max_cost: float = 3, template: BaseDtwTemplate = CloneFactory(InterpolatedDtwTemplate())
) -> None:
self.max_cost = max_cost
self.template = template
def self_optimize(self, dataset: MyDataset, **kwargs):
if not isinstance(self.template, TrainableTemplateMixin):
raise ValueError(
"The template must be optimizable! If you are using a fixed template (e.g. "
"BarthOriginalTemplate), switch to an optimizable base classe."
)
# Our training consists of cutting all strides from the dataset and then creating a new template from all
# strides in the dataset
# We expect multiple datapoints in the dataset
sampling_rate = dataset[0].sampling_rate_hz
# We create a generator for the data and the stride labels
data_sequences = (
self._convert_cord_system(datapoint.data, datapoint.groups[0][1]).filter(like="gyr")
for datapoint in dataset
)
stride_labels = (datapoint.segmented_stride_list_ for datapoint in dataset)
stride_generator = iterate_region_data(data_sequences, stride_labels)
self.template.self_optimize(
stride_generator, columns=["gyr_pa", "gyr_ml", "gyr_si"], sampling_rate_hz=sampling_rate
)
return self
def _convert_cord_system(self, data, foot):
converter = {"left": convert_left_foot_to_fbf, "right": convert_right_foot_to_fbf}
return converter[foot](data)
def run(self, datapoint: MyDataset):
# `datapoint.groups[0]` gives us the identifier of the datapoint (e.g. `("test", "left")`).
# And `datapoint.groups[0][1]` is the foot.
data = self._convert_cord_system(datapoint.data, datapoint.groups[0][1])
dtw = BarthDtw(max_cost=self.max_cost, template=self.template)
dtw.segment(data, datapoint.sampling_rate_hz)
self.segmented_stride_list_ = dtw.stride_list_
self.cost_func_ = dtw.cost_function_
return self
Comparison#
To see the effect of the optimization, we will compare the output of the optimized pipeline with the output of the default pipeline. As it is not the goal of this example to perform any form of actual evaluation of a model, we will just compare the number of identified strides and the cost functions to show, that the optimization had an impact on the output.
For a fair comparison, we must use some train data to optimize the pipeline and then compare the outputs only on a separate test set.
from sklearn.model_selection import train_test_split
ds = MyDataset()
train_set, test_set = train_test_split(ds, train_size=0.5, random_state=0)
(train_set.groups, test_set.groups)
([MyDatasetGroupLabel(participant='test', foot='left')], [MyDatasetGroupLabel(participant='test', foot='right')])
The Baseline#
For our baseline, we will use the pipeline, but will the use
BarthOriginalTemplate.
from gaitmap.data_transform._scaler import TrainableAbsMaxScaler
pipeline = MyPipeline(template=BarthOriginalTemplate())
# We use the `safe_run` wrapper instead of just run. This is always a good idea.
results = pipeline.safe_run(test_set)
print("Number of Strides:", len(results.segmented_stride_list_))
Number of Strides: 11
Optimization#
To optimize the pipeline, we will not call self_optimize directly, but use the
Optimize wrapper.
It has the same interface as other optimization methods like GridSearch.
Further, it makes some checks to catch potential implementation errors of our self_optimize method.
Note, that the optimize method will perform all optimizations on a copy of the pipeline. The means the pipeline object used as input will not be modified.
We can change how the template should be generated by changing the template parameter of the pipeline.
Here we change the scaling, so that the template data will be divided by its maximum value.
This value will be calculated when calling self_optimize and then used by
:class:`~gaitmap.stride_segmentation.BarthDtw internally to also scale the actual data correctly to match the
template.
from tpcp.optimize import Optimize
template = InterpolatedDtwTemplate(scaling=TrainableAbsMaxScaler())
pipeline = MyPipeline(template=template)
# Remember we only optimize on the `train_set`.
optimized_pipe = Optimize(pipeline).optimize(train_set)
optimized_results = optimized_pipe.safe_run(test_set)
print("Number of Strides:", len(optimized_results.segmented_stride_list_))
Number of Strides: 26
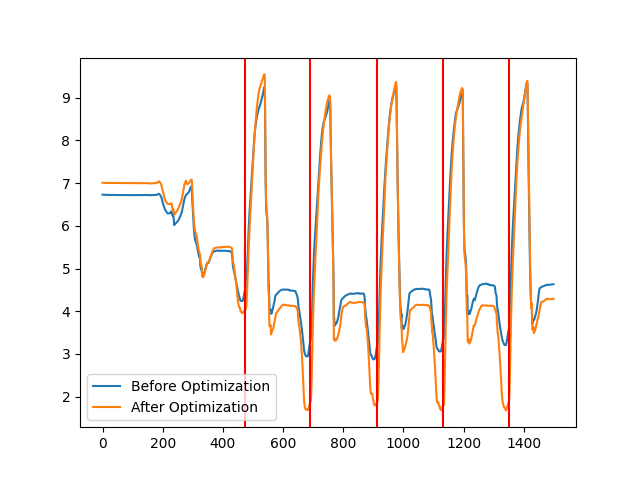
We can see that the optimized version finds far more strides. This is to be expected, as the generated template will be more similar to the test data than the default template. We can see that even more clearly when comparing the cost functions of the two predictions. The cost function of the optimized pipeline has smaller values at the minima that mark the start and the end of each stride, hence, indicating a larger similarity between template and signal.
Note
A similar level of performance can be achieved by optimizing other parameters (like max_cost) of the
pipeline without changing the template.
However, this is out of scope for this example.
import matplotlib.pyplot as plt
plt.figure()
plt.plot(results.cost_func_[:1500], label="Before Optimization")
plt.plot(optimized_results.cost_func_[:1500], label="After Optimization")
first_strides = test_set.segmented_stride_list_[test_set.segmented_stride_list_[["start"]] < 1500]
for s in first_strides["start"]:
plt.axvline(s, c="r")
plt.legend()
plt.show()
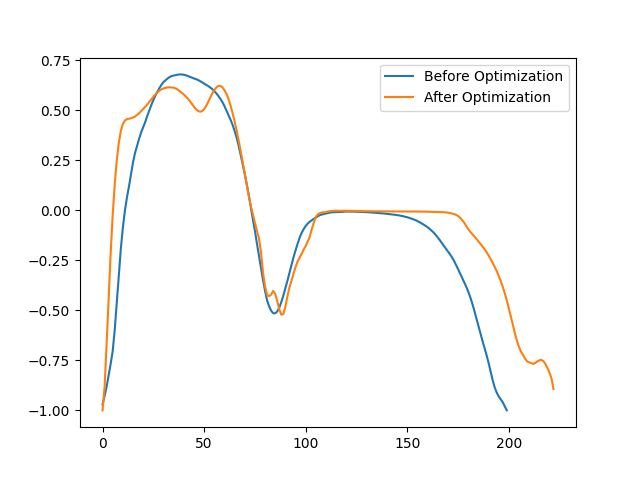
We can see the differences in the trained template as well.
Here only the gyr_ml axis is plotted for simplicity.
The optimized template contains much more “detail” of the individuals gait.
Note, that this is not generally “good”, as this template is overfitted to this participant and will not generalize
well.
plt.figure()
plt.plot(results.template.get_data()["gyr_ml"], label="Before Optimization")
plt.plot(optimized_results.template.get_data()["gyr_ml"], label="After Optimization")
plt.legend()
plt.show()
Final Notes#
In this example we only modified the template of the pipeline.
For the BarthDtw algorithm the template can be considered the model.
However, there are additional parameters that can be optimized to modify the output of the method.
If we want to train a new template and optimize these parameters (e.g. via a GridSearch), a train/test/validation
split or even better GridSearchCv should be used.
Total running time of the script: ( 0 minutes 3.951 seconds)
Estimated memory usage: 9 MB